Code
library(tidyverse)
library(readxl)
library(VIM) #для визуализации пропусков
library(rvest) #для копирования таблицы из веба
library(pracma) #для подсчета скользящей среднейДанные с ближайшей метеостанции (п. Бахта) были проанализированы на предыдущем шаге. Здесь получим данные с других 6 метеостанций.
К сожалению, таких данных гораздо меньше и формат отличается, поэтому обработка тоже будет отличаться.
На выходе получаем большие таблицы, где для каждой станции рассчитаны среднемесячные и среднегодовые температуры, суммы осадков, глубины снежного покрова и аномалии (то есть отклонения от среднего базового за 1961-1990) для каждого параметра. Также рассчитаны средние базовые значения, средние за 2013-2022, стандартные ошибки среднего, скользящее среднее за 1976-2023.
library(tidyverse)
library(readxl)
library(VIM) #для визуализации пропусков
library(rvest) #для копирования таблицы из веба
library(pracma) #для подсчета скользящей среднейreading_XXI - функция, по своей сути напоминающая функцию read_files с предыдущего шага, с некоторыми отличиями. Например, в столбце Station сохраняется название метеостанции (загружается из названия файла)
reading_XXI <- function(name_of_df){
result <- read_excel(name_of_df) |>
select(1,2,28) |>
rename(Local_time = 1) |>
mutate(Local_time = as_datetime(Local_time, format="%d.%m.%Y %R")) |>
mutate(Year = year(Local_time),
Month = month(Local_time),
Day = mday(Local_time)) |>
rename(Sn = "E'",
Tavg = "T") |>
group_by(Year, Month, Day) |>
summarise(Sn = as.factor(str_flatten(Sn, ", ", na.rm = T)),
Tavg = mean(Tavg, na.rm=T)) |>
arrange(Year, Month, Day) |>
mutate(Station = str_match(name_of_df, "station/(.*?).xls")[2])
return(result)
}reading_XX - простая функция для считывания txt-файлов. Вынесена в отдельную функцию, чтобы было удобнее оборачивать в map.
parsing_html_table - функция для считывания таблиц из html-файлов (гораздо удобнее, чем копировать и вставлять в excel вручную)
Есть еще парочка функций для расчета стандартного отклонения и скользящего среднего.
reading_XX <- function(x){read_table2(x, col_names = F)}
parsing_html_table <- function(http){
df <- read_html(http)
year <- df |>
html_element(".chronicle-table-left-column") |>
html_table() |>
slice(-1)
temper <- df |>
html_element(".chronicle-table") |>
html_table() |>
slice(-1)
result <- cbind(year, temper)
colnames(result) <- c("Year", c(1:12), "annualy")
result <- result |>
select(-annualy) |>
pivot_longer(-Year, values_to = "Tavg", names_to = "Month") |>
filter(Year %in% c(1961:2004) | (Year == 2005 & Month==1)) |>
mutate_at(c(1:3), .funs=as.numeric)
return(result)
}
std <- function(x){ sd(x)/sqrt(length(x)) } # Стандартная ошибка - стандартное отклонение/квадратный корень из числа наблюдений
# exponential_smooth <- function(x) { es(x, model="AAdN",h=8,holdout=FALSE,cfType="MSE")$fitted}
means_smooth <- function(x, n) {
pracma::movavg(x, n=10, type=c("s"))
}Импортируем данные за 2005-2023 гг., осредним до суточного разрешения и проверим их на пропуски.
# Данные 2005-2023 (6 станций(без бахты)) суточное разрешение ----------------------------------------------
paths <- list.files("../initial_data/climate/2005_2023_seven_station", pattern = "[.]xls$", full.names = TRUE)
six_station_2005_2023 <- paths |>
map_dfr(reading_XXI)
rm(reading_XXI, paths)
aggr(six_station_2005_2023, prop = F, numbers = T) #отлично, пропусков нет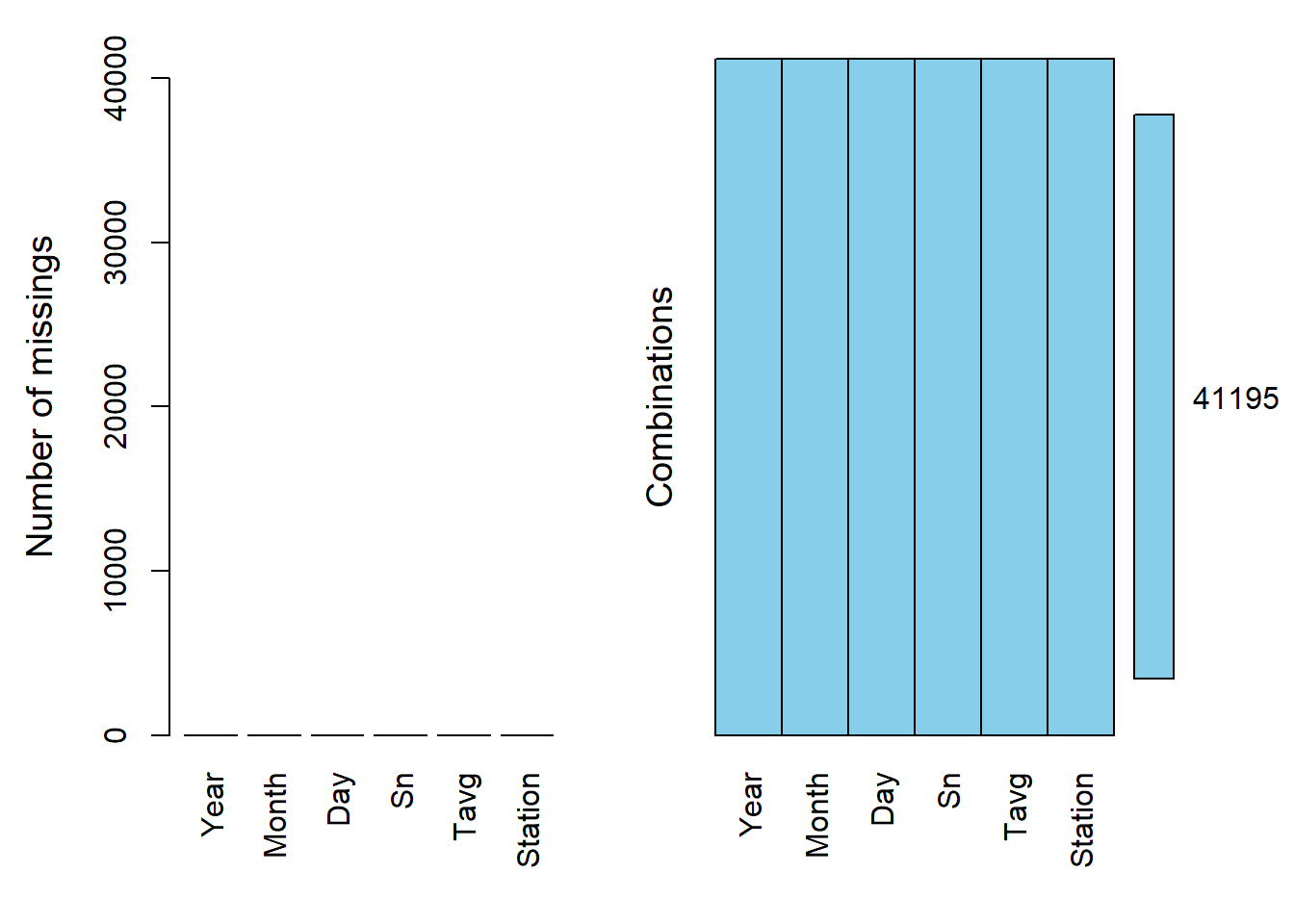
Теперь осредним до месячного разрешения.
six_station_2005_2023_monthly <- six_station_2005_2023 |>
group_by(Station, Year, Month) |>
summarise(Tavg = mean(Tavg))Импортируем данные с 1961 года (они изначально месячного разрешения, источник - МЦД)
paths <- list.files("../initial_data/climate/monthly_all_station/", pattern = "[.]txt$", full.names = TRUE) # Просканировали все файлы в директории
four_station_obninsk <- paths |>
map(reading_XX) |>
list_rbind() |>
rename(Station = X1) |>
mutate(Station = case_when(
Station == "23274" ~"igarka",
Station == "23678" ~ "verkhneimbatsk",
Station == "23472" ~ "turukhansk",
.default = "bor"))
colnames(four_station_obninsk) <- c("Station", "Year", "1", "2", "3", "4", "5", "6", "7","8", "9", "10", "11", "12")
rm(paths)
four_station_obninsk <- four_station_obninsk |>
pivot_longer(-c(Station, Year), names_to = "Month", values_to = "Tavg") |>
mutate(Month = as.numeric(Month)) |>
filter(Year %in% c(1961:2004) | (Year == 2005 & Month==1))Найдем данные об оставшихся двух метеостанциях. Загрузка парсингом веб-страниц.
# ----------------------------------------
vorogovo <- parsing_html_table("http://www.pogodaiklimat.ru/history/23973.htm") |>
mutate(Station = "vorogovo")
yartsevo <- parsing_html_table("http://www.pogodaiklimat.ru/history/23987.htm") |>
mutate(Station = "yartsevo")Объединим данные со всех метеостанций в 1 датафрейм. Добавим в тот же датафрейм осредненную по всем метеостанциям информацию. Описание снежного покрова по 6 станциям сохраним в отдельный csv. Удалим промежуточные переменные.
# 6 станций (кроме Бахты). Данных об осадках и глубине снега нет.
six_station <- rbind(six_station_2005_2023_monthly, four_station_obninsk, vorogovo, yartsevo) |>
arrange(Station, Year, Month) |>
filter(Year %in% c(1961:2022) | (Year %in% c(1961:2023) & Month <7)) |>
mutate(Pr = NA, Sn = NA) |>
select(Station, Year, Month, Tavg, Pr, Sn)
# предобработанные ранее данные из Бахты
bakhta_monthly <- read_csv2("../initial_data/climate/cleaned/Bakhta_monthly_1966-1976_replaced_by_average_Bor_Verkhn.csv") |>
mutate(Station = "bakhta") |>
select(Station, Year, Month, Tavg, Pr, Sn)
# данные по всем метеостанциям
all_station <- rbind(six_station, bakhta_monthly) |>
arrange(Station, Year, Month)
average_temp_by_7_station <- all_station |>
group_by(Year, Month) |>
summarise(Tavg = mean(Tavg)) |>
mutate(Station = "average_by_all_station")
# данные по всем метеостанциям + осредненные
seven_station <- rbind(all_station, average_temp_by_7_station)
# данные о характеристиках снега по 6 станциям (кроме Бахты)
snow_quality_six_station <- six_station_2005_2023 |>
select(-Tavg) |>
rename(Sn_description = Sn)
#write_csv2(snow_quality_six_station, "../initial_data/climate/cleaned/snow_quality_six_station.csv")
rm(all_station, average_temp_by_7_station, bakhta_monthly, four_station_obninsk, six_station,
six_station_2005_2023, six_station_2005_2023_monthly, vorogovo, yartsevo)Аномалии были рассчитаны как отклонения от среднего значения на базовом (1961-1990) периоде. Финальные датафреймы сохранены в csv-файлы. См. комментарии в коде
# Расчет аномалий, среднего базового и тд ---------------------------------
# Осреднение --------------------------------------------------------------
annualy_T_avg_Pr <- seven_station |>
rename(T_=Tavg) |> # не менять, иначе не будут считаться SE
group_by(Station, Year) |>
summarise(Tavg = mean(T_),
Tavg_SE = std(T_),
Pr = sum(Pr)) # SE для Pr не считаем, так как там не среднее, а сумма
#Для снежного покрова сделаем отдельный расчет среднегодового, не учитывая летние месяцы
annualy_Sn <- seven_station |>
rename(Sn_=Sn) |> # не менять, иначе не будут считаться SE
filter(Month %in% c(1:5,9:12)) |>
group_by(Station, Year) |>
summarise(Sn = mean(Sn_),
Sn_SE = std(Sn_))
annualy <- annualy_T_avg_Pr |>
left_join(annualy_Sn, by = c("Station", "Year"))
rm(annualy_Sn, annualy_T_avg_Pr, six_station_monthly, Bakhta_monthly, tavg_by_seven_station)
# Расчет базовых (опорных) значений ---------------------------------------
base_annualy <- annualy |>
filter(Year %in% c(1961:1990)) |>
group_by(Station) |>
summarise(across(c(Tavg, Sn, Pr), list(
base = mean,
base_SE = std
)))
base_monthly <- seven_station |>
filter(Year %in% c(1961:1990)) |>
group_by(Station, Month) |>
summarise(across(c(Tavg, Sn, Pr), list(
base = mean,
base_SE = std
)))
# Средние значения за последнее десятилетие -------------------------------
last_decade_annualy <- annualy |>
filter(Year %in% c(2013:2022)) |> #2023 год не берем, так как нет полных данных
group_by(Station) |>
summarise(across(c(Tavg, Sn, Pr), list(
last_decade = mean,
last_decade_SE = std
)))
last_decade_monthly <- seven_station |>
filter(Year %in% c(2013:2022)) |>
group_by(Station, Month) |>
summarise(across(c(Tavg, Sn, Pr), list(
last_decade = mean,
last_decade_SE = std
)))
# Расчет аномалий, скользящего среднего, линейного тренда с 1976 года и разницы между базовой и последним десятилетием --------
annualy_anomaly <- annualy |>
left_join(base_annualy, by = "Station") |>
group_by(Station) |>
mutate(T_anomaly = Tavg-Tavg_base,
Sn_anomaly = Sn-Sn_base,
Pr_anomaly = Pr-Pr_base) |>
left_join(last_decade_annualy, by = "Station") |>
mutate(T_diff = Tavg_last_decade-Tavg_base,
Sn_diff = Sn_last_decade-Sn_base,
Pr_diff = Pr_last_decade-Pr_base) |>
mutate(across(c(T_anomaly, Pr_anomaly, Sn_anomaly, Tavg, Pr, Sn), list(
roll_mean = means_smooth
))) |>
mutate(across(contains("roll_mean"),
list(from_1976 = \(x) c(rep(NA, 15), x[16:length(x)])
)))
monthly_anomaly <- seven_station |>
left_join(base_monthly, by = c("Station", "Month")) |>
group_by(Station, Month) |>
mutate(T_anomaly=Tavg-Tavg_base,
Sn_anomaly=Sn-Sn_base,
Pr_anomaly=Pr-Pr_base) |>
left_join(last_decade_monthly, by=c("Station","Month"))|>
mutate(T_diff = Tavg_last_decade-Tavg_base,
Sn_diff = Sn_last_decade-Sn_base,
Pr_diff = Pr_last_decade-Pr_base) |>
mutate(across(c(T_anomaly, Pr_anomaly, Sn_anomaly, Tavg, Pr, Sn), list(
roll_mean = means_smooth
))) |>
mutate(across(contains("roll_mean"),
list(from_1976 = \(x) c(rep(NA, 15), x[16:length(x)])
)))
#write_csv2(annualy_anomaly, "../initial_data/climate/cleaned/annualy_anomaly.csv")
#write_csv2(monthly_anomaly, "../initial_data/climate/cleaned/monthly_anomaly.csv")