Code
library(tidyverse)
library(readxl)
library(plotly)
library(VIM) # использовал для визуализации пропусков
library(imputeTS) # Для интерполяции пропусковМетеостанция п. Бахта - ближайшая к интересующему месту. Данные были получены из открытых источников, таких как rp5 (2005-2023 годы, 1 измерение раз в 3 часа), а также предоставлены Мировым центром данных Всероссийского научно-исследовательского института гидрометеорологической информации (суточное разрешение).
library(tidyverse)
library(readxl)
library(plotly)
library(VIM) # использовал для визуализации пропусков
library(imputeTS) # Для интерполяции пропусковread_files - функция, которая:
считывает файлы excel, полученные с сайта rp5
разбивает столбец со временем на отдельные столбцы (год, месяц, день)
отбирает необходимые для дальнейшего анализа столбцы:
Year - Год
Month - месяц
Day - день
Tavg - температура
Pr - количество осадков
Sn - глубина снежного покрова
Sn_description - описание снежного покрова
очищает столбец Pr от строковых значений
производит преобразование типов столбцов, где это необходимо
Вычисляет среднесуточные значения температур и глубин снежного покрова, а также сумму осадков. Sn_desription - описание снежного покрова делается несколько раз в сутки, но не каждые 3 часа, поэтому многие строки содержат пропущенные значения. Функция объединяет все наблюдения в 1, перечисляя их через запятую.
read_files <- function(x){
df <- read_excel(x) |>
mutate(Local_time = as_datetime(Local_time, format = "%d.%m.%Y %R")) |>
mutate(Year = year(Local_time),
Month = as.factor(month(Local_time)),
Day = mday(Local_time)) |>
select(Year, Month, Day, Tavg=T, Pr=RRR, Sn=sss, Sn_description = `E'`) |>
mutate(Pr = case_when(Pr == "Осадков нет" | Pr == "Следы осадков" ~ "0",
.default = Pr)) |>
arrange(Year, Month, Day) |>
mutate(across(c(Year:Day, Sn_description), as.factor),
across(Tavg:Sn, as.numeric)) |>
group_by(Year, Month, Day) |>
summarise(
Tavg = mean(Tavg, na.rm = T),
Pr = sum(Pr, na.rm = T), # Потому что это накопленные осадки, нужно суммировать
Sn = mean(Sn, na.rm = T),
Sn_description = as.factor(str_flatten(Sn_description, ", ", na.rm = T))
)
return(df)
}interactive_graph - функция, которая принимает на вход следующие аргументы:
df - необходимый датафрейм
parametr - столбец, который будет отображен на графике
title - строка-заголовок графика
На выходе - интерактивный график, построенный с помощью пакета plotly
interactive_graph <- function(df, parametr, title) {
plot_ly(df, type = "scatter", mode = "lines") |>
add_trace(x = ~Date, y = ~df[[parametr]], name = title) |>
layout(
showlegend = F, title = title,
xaxis = list(rangeslider = list(visible = T))
)
}Данные, предоставленные Мировым центром данных (МЦД) и rp5 имеют различный формат, поэтому загрузим их отдельно друг от друга. Из МЦД было получено 2 файла: с данными о температуре и осадках и, второй, с данными о снежном покрове. Загрузим их, отберем необходимые столбцы и объединим в один датафрейм:
obninsk_temperature <- read_excel("../initial_data/climate/1961_2005/23776_TTTR.xlsx") |>
select(
Year = год,
Month = месяц,
Day = день,
Tavg = Тср,
Pr = осадки
)
obninsk_snow <- read.csv2("../initial_data/climate/1961_2005/23776_snow.csv", fileEncoding = "windows-1251") |>
select(
Station = Станция,
Year = Год,
Month = Месяц,
Day = День,
Sn = Высота_снежного_покрова,
Sn_description = Снежный_покров_.степень_покрытия
)
obninsk <- obninsk_temperature |>
left_join(obninsk_snow, by = c("Year", "Month", "Day")) |>
select(-Station) |>
filter(Year<2005 | (Year==2005 & Month == 1))На всякий случай проверим, нет ли избыточных строк в какой-либо год?
nrow(obninsk |>
group_by(Year) |>
summarise(N = n()) |>
filter(N>366)) == 0 #Все годы нормальной продолжительности[1] TRUErm(obninsk_snow, obninsk_temperature) # удалим промежуточные переменныеТеперь загрузим данные, полученные с rp5.ru, и объединим их с данными из МЦД и снова проверим, нет ли лишних строк? (то есть все годы должны быть “нормальной” продолжительности)
# Данные rp5.ru -----------------------------------------------------------
paths <- list.files("../initial_data/climate/2005_2023", pattern = "[.]xls$", full.names = TRUE) # Просканировали все файлы в директории
rp5 <- paths |>
map_df(read_files) # объединили в 1 датафрейм все загруженные файлы
rm(paths)
# Объединенные данные -----------------------------------------------------
climate <- rbind(obninsk, rp5)
nrow(climate |>
group_by(Year) |>
summarise(N = n()) |>
filter(N>366))==0 #Все годы нормальной продолжительности[1] TRUErm(obninsk, rp5)Проверим данные на наличие пропусков
summary(climate) # 271 пропуск средней температуры, 3423 пропуса снега, 1458 пропуск осадков Year Month Day Tavg
Length:22807 Length:22807 Length:22807 Min. :-54.400
Class :character Class :character Class :character 1st Qu.:-15.691
Mode :character Mode :character Mode :character Median : -1.700
Mean : -4.493
3rd Qu.: 7.300
Max. : 28.400
NA's :271
Pr Sn Sn_description
Min. : 0.000 Min. : 0.0 Length:22807
1st Qu.: 0.000 1st Qu.: 0.0 Class :character
Median : 0.400 Median : 26.0 Mode :character
Mean : 1.488 Mean : 173.2
3rd Qu.: 1.600 3rd Qu.: 53.0
Max. :813.000 Max. :9999.0
NA's :1458 NA's :3089 Удобно визуализировать пропуски с помощью пакета VIM
aggr(climate, prop = F, numbers = T) # Визуализация пропусков из пакета VIM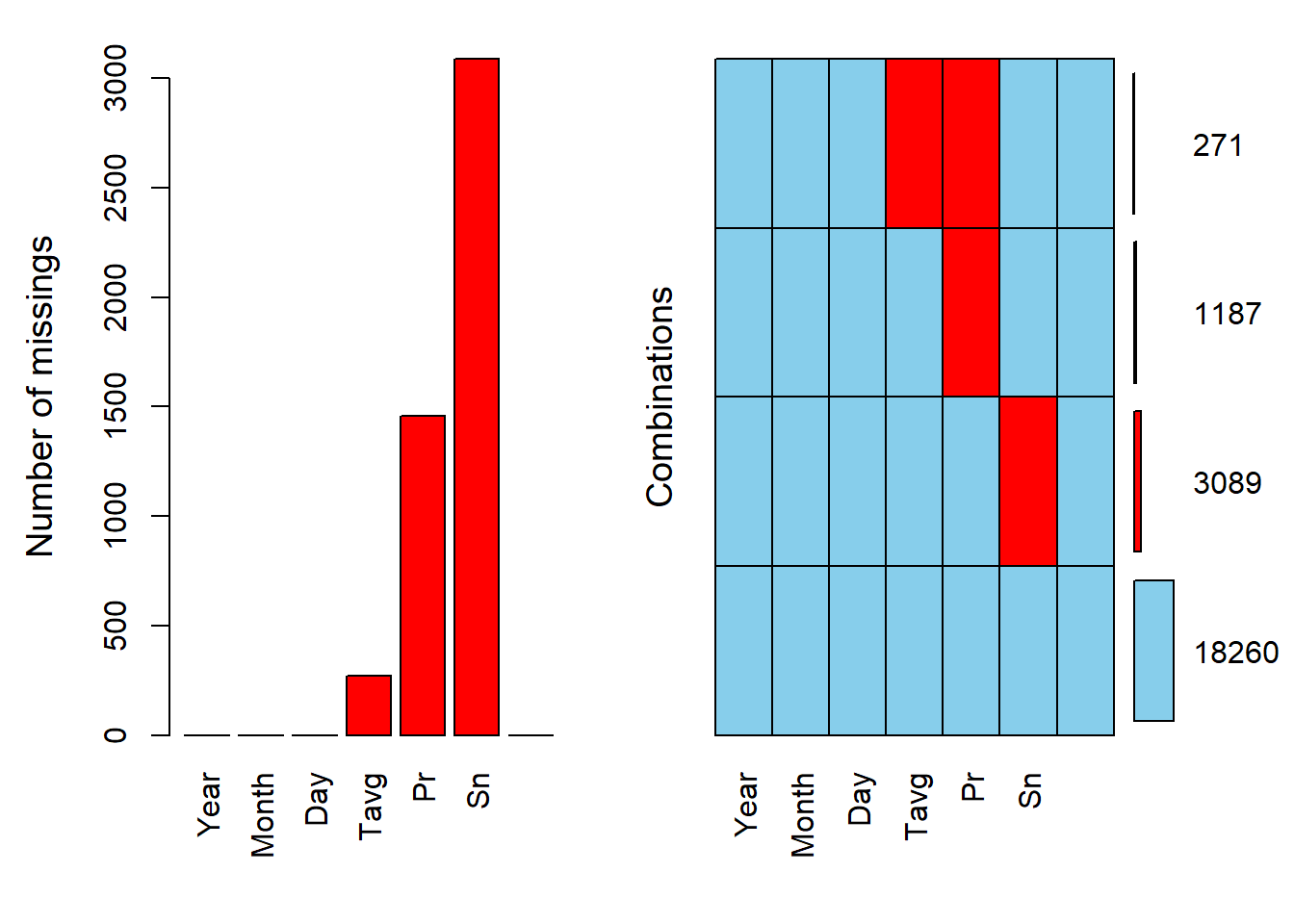
Работаем с пропусками следующим образом:
Если Sn=9999.0, его надо заменить на NA
Снега в летние месяцы быть не может
Если осадки NA, а снег и температура не пропущены, то, скорее всего, осадков не было (=0)
Оставшиеся пропуски удалим методом линейной интерполяции (замена с помощью уравнения линейной регрессии y = kx+b) (na_interpolation из пакета imputeTS)
climate <- climate |>
mutate(Sn = case_when(
Sn == 9999 ~ NA,
Sn == "NaN" ~ NA,
.default = Sn
)) |>
mutate(Sn = case_when(
Month %in% c(6:8) & is.na(Sn) ~ 0,
.default = Sn
)) |>
mutate(Pr = case_when(
is.na(Pr) & is.na(Tavg) == F & is.na(Sn) == F ~ 0,
.default = Pr
)) |>
mutate(across(Tavg:Sn, na_interpolation))Проверим, что получилось
summary(climate) Year Month Day Tavg
Length:22807 Length:22807 Length:22807 Min. :-54.400
Class :character Class :character Class :character 1st Qu.:-15.700
Mode :character Mode :character Mode :character Median : -1.700
Mean : -4.543
3rd Qu.: 7.100
Max. : 28.400
Pr Sn Sn_description
Min. : 0.000 Min. : 0.00 Length:22807
1st Qu.: 0.000 1st Qu.: 0.00 Class :character
Median : 0.300 Median : 13.00 Mode :character
Mean : 1.415 Mean : 24.97
3rd Qu.: 1.500 3rd Qu.: 49.00
Max. :813.000 Max. :127.00 aggr(climate, prop = F, numbers = T)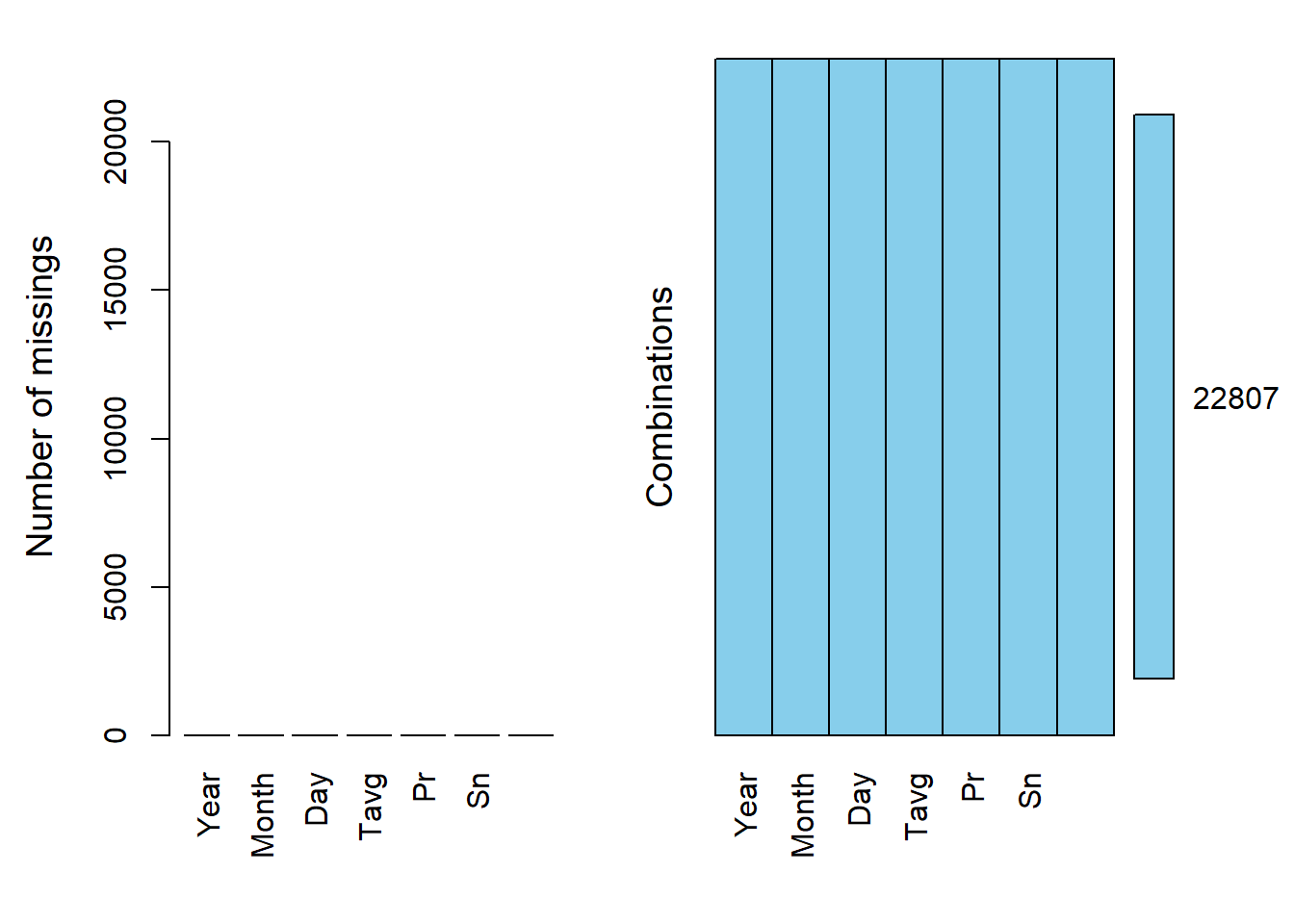
Отлично, пропуски очищены.
Для средних температур есть проблемы с летними месяцами с 1966 по 1976 годы
climate <- climate |>
mutate(Date = make_date(Year, Month, Day)) # датафрейм с датами в формате дат,чтобы plot_ly смог построить интерактивный график
interactive_graph(climate, parametr = 'Tavg', "Temperature") Проверка данных об осадках на выбросы: выбросы есть
interactive_graph(climate, parametr = 'Pr', "Precipitations") # Есть выбросыСовсем нереальные пики заменил значениями, похожими на соседние
climate <- climate |>
mutate(Pr = case_when(
Pr %in% c(204.3, 202) ~ 3,
Pr == 813 ~ 2,
.default = Pr
))
interactive_graph(climate, parametr = 'Pr', "Precipitations") # стало лучшеСо снегом более-менее нормально.
Случайные пропуски не появились.
Сохраняем предобработанный файл с информацией суточного разрешения
interactive_graph(climate, parametr= 'Sn', "Snow depth")aggr(climate, prop = F, numbers = T) # Пропусков больше нет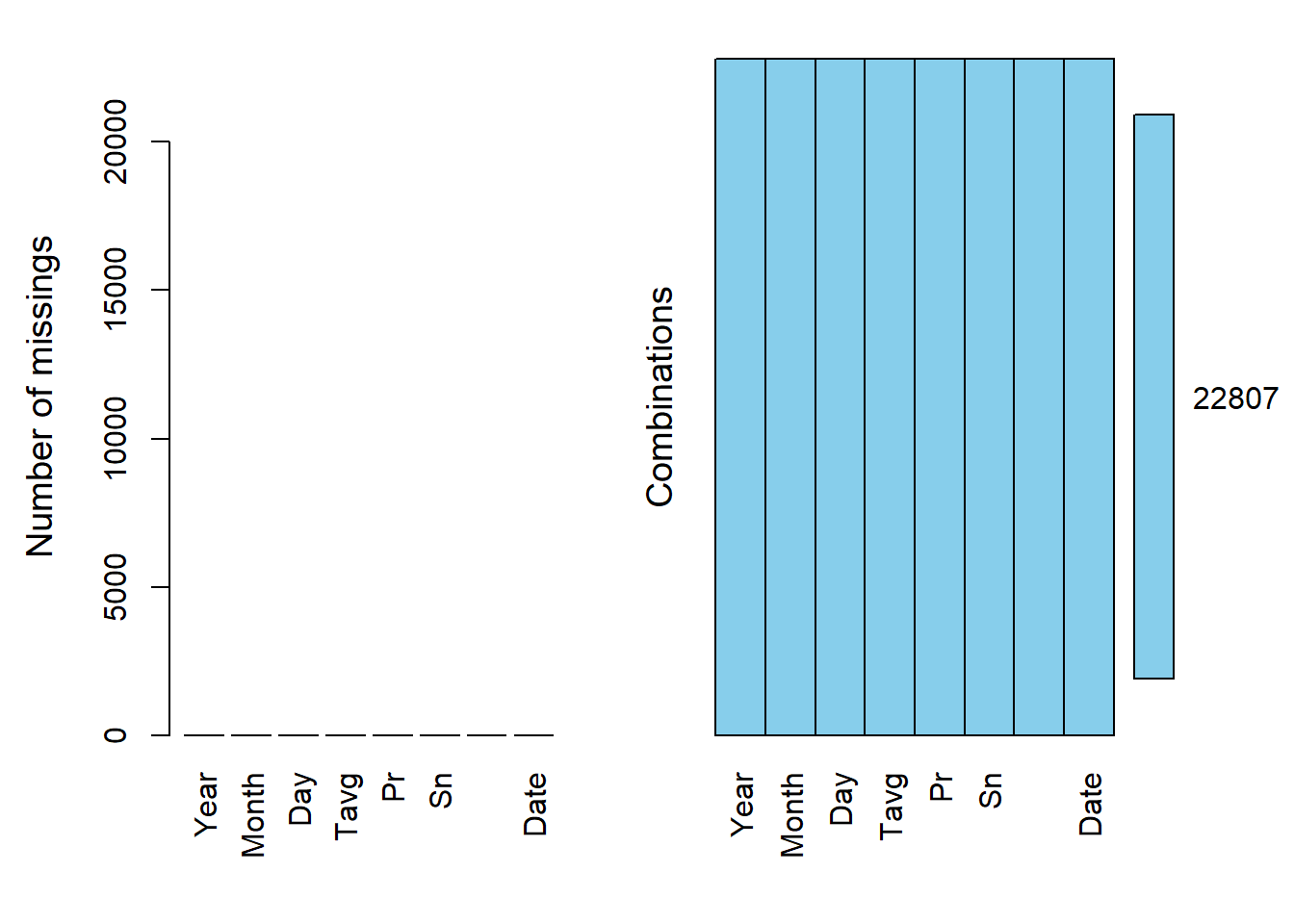
#write_csv2(climate, "../initial_data/climate/cleaned/Bakhta_daily_problem_with_summer_1966-1976.csv")Видим, что есть проблемы с летними месяцами
Bakhta_monthly <- climate |>
group_by(Year, Month) |>
summarise(across(c(Tavg, Sn), mean),
Pr = sum(Pr)) |> # Накопленное количество осадков
mutate(across(is.character, as.numeric)) |>
arrange(Year, Month) |>
mutate(Date = make_date(Year, Month))
interactive_graph(Bakhta_monthly, "Tavg", "Temperature")Загрузим данные о среднемесячных температурах с метеостанций п. Бор и Верхнеимбатск. Это ближайшие к Бахте метеостанции.
Построим график и сохраним данные месячного разрешения в отдельный файл для последующего анализа.
Bor_monthly <- read_delim("../initial_data/climate/monthly/Bor_monthly.txt",
delim = ";", col_types = "n",
col_names = c("Station", "Year", 1:12)) |>
select(-Station) |>
mutate_all(as.numeric) |>
pivot_longer(cols = -c(Year), names_to = "Month", values_to = "Tavg") |>
mutate(Date = make_date(Year, Month))
interactive_graph(Bor_monthly, parametr = 'Tavg', "Temperature in Bor")Verkhneimbatsk_monthly <- read_delim("../initial_data/climate/monthly/Verkhneimbatsk_monthly.txt",
delim = ";", col_types = "n",
col_names = c("Station", "Year", 1:12)) |>
select(-Station) |>
mutate_all(as.numeric) |>
pivot_longer(cols = -c(Year), names_to = "Month", values_to = "Tavg") |>
mutate(Date = make_date(Year, Month))
interactive_graph(Verkhneimbatsk_monthly, parametr = 'Tavg', "Temperature in Verkhneimbatsk")С ними более-менее все в порядке.
Поэтому заменим данные за июнь-сентябрь 1966-1976 гг. в Бахте на осредненные по Бору и Верхнеимбатску, сохраним данные в отдельный файл для дальнейшего анализа.
Bor_Verkhn <- Bor_monthly |>
left_join(Verkhneimbatsk_monthly, by = c("Year", "Month")) |>
select(Year, Month, Bor_tavg = Tavg.x, Verkhn_tavg = Tavg.y) |>
filter(Year %in% c(1966:1976), Month %in% c(6:9)) |>
mutate(across(c(Year, Month), as.integer)) |>
group_by(Year, Month) |>
summarise(Tavg = mean(Bor_tavg, Verkhn_tavg))
Bakhta_monthly_new <- Bakhta_monthly |>
ungroup() |>
mutate(across(c(Year, Month), as.integer)) |>
left_join(Bor_Verkhn, by = c("Year", "Month")) |>
mutate(Tavg = ifelse(is.na(Tavg.y) == F, Tavg.y, Tavg.x)) |>
select(Year, Month, Tavg, Sn, Pr, Date)
# График среднемесячных температур в Бахте (1966-1976гг 6-8 мес заменены на оср Бор-Верхнеимбатск)
interactive_graph(Bakhta_monthly_new, "Tavg", "Temperature in Bakhta")rm(Bor_monthly, Bor_Verkhn, Verkhneimbatsk_monthly, climate)
#write_csv2(Bakhta_monthly_new, "../initial_data/climate/cleaned/Bakhta_monthly_1966-1976_replaced_by_average_Bor_Verkhn.csv")